Vzdělávání
05.07.2022
Marián Kristeľ
Cloudové rozšíření Divi Cloud
Co je Divi Cloud a proč by tě mohlo zajímat? V tomto článku ti představíme tuto novinku pro WordPress od Elegant Themes a pomůžeme ti rozhodnout se, jestli je to pro tebe to pravé. Jaké má možnosti? Co je to? Čti dál a hned se to dozvíš.
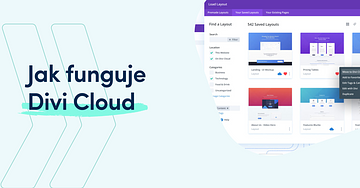
Divi Cloud je v podstatě jako Disk Google nebo Dropbox pro tvé Divi layouty, řádky a moduly Divi (a brzy i další obsah, jako jsou šablony pro tvorbu témat, nastavení přizpůsobení a mnoho dalšího).
Divi CloudDivi Cloud je super pomůcka pro všechny, kdo manažují více Divi stránek. Buď ty sám máš několik svých stránek, nebo jsi developer a vytváříš stránky pro klienty. Divi Cloud si umíš představit jako Dropbox nebo OneDrive, ale pro své Divi stránky. Umíš si do cloudu něco uložit a následně to na svých stránkách použít.
Na začátku Divi cloud podporuje přidávání layoutů, modulů, rows a sections. Později plánují rozšířit možnosti i na jiné aspekty Divi.
Vytořil si nebo koupil si nějaké Layout? Přidej ho do Divi stránky a následně ho přidej do Divi cloud. Nyní se umíš přihlásit na jiné stránce a přidat tento Layout. Všechno si umíš přejmenovat, lépe a jednodušeji organizovat. Všemu, co sis uložil umíš přidávat tagy a tak umíš snadněji vyhledávat. Umíš si označit i oblíbené položky.
Když přidáš novou položku do Divi, například přidáš layout, nebo nějakou sekci, tak Divi udělá automaticky screenshot a vytvoří ti náhledový obrázek. Tím pádem je vše přehledné i vizuální 🙂
CenaJako člen Elegant Themes – jako předplatitel Divi tématu máš přístup k Divi cloudu zdarma. Zdarma si umíš uložit 50 položek. Pokud potřebuješ více položek, tak si musíš Divi cloud předplatit.
K datu psaní článku je měsíční cena 8 Eur, nebo 6 Eur, pokud zaplatíš za celý rok najednou - celkem 72 Eur za rok. Aktuální ceny si umíš prohlédnout na tomto linku.
Praktická ukázkaSlova jsou hezká, ale pojďme si to ukázat prakticky. V této praktické ukázce si ukážeme, jak aktualizovat Divi téma, následně si uložíme nějakou položku do Divi cloud. Přihlásíme se na jinou web stránku a použijeme uloženou položku tam. Pojďme na to.
Nejprve si musíš udělat update Divi témata, abys měl přístup k novým možnostem. Ve WordPressu pojedeme Appearance – Themes – update now.
Následně pojedeme na tu stránku, kde si chceme uložit do cloudu nějakou její část. V mém případě půjdu na tu část, kde mám fotku a odkazy na sociální sítě a podobně. Tuto část si chci uložit do Cloudu. Spustím Visual Builder.[Visual Builder v Divi Cloud]Chci si uložit celou sekci. Přijdu nad možnosti a vyberu možnost Save To Divi Cloud.[Save to Divi Cloud]Tento způsob by fungoval, kdybychom byli přihlášeni do účtu.[Prihlásenie do Divi Cloud]Pro přihlášení přejdi na leckteré Plus – tedy na přidání sekce, modulu a podobně. Klikněte na Add From Library.[Ako sa prihlásiť]Otevře se ti okno, kde máš možnost přidávat věci z Library. V pravém horním rohu najdeš tlačítko Sign In To Divi Cloud.[Prihlasovacie tlačidlo]Klikneš a přihlásíš se se svým účtem do Elegant Themes. Nemusíš mít speciální Divi Cloud účet ani předplatné. Stačí, když máš Elegant Themes účet a umíš si Divi Cloud vyzkoušet zdarma. Mně se podařilo přihlásit až podruhé. Tak to zkus i víckrát, pokud to napoprvé nevyšlo.
Okno zavřeme a znovu se pokusíme naši sekci Přidat do Divi Cloud.[Pridanie do Divi Cloud]Klepnu na Save to Divi Cloud. Vyplním data a vidím, že Save to Divi Cloud je zapnuto. Kliknu na Save to Divi Cloud a počkám.
Nyní, pokud se pokusím přidat novou sekci přes Plus tlačítko a vyberu Add From Library, tak v seznamu budu mít uloženou moji sekci s náhledovým obrázkem as ikonou modrého obláčku, která nám značí, že tato sekce je uložena v Divi Cloudu.[Sekcia uložená v Divi Cloud]Nyní přejdu na úplně jinou Web stránku, která je také pod Divi tématem. I toto téma musí být aktuální, aby mělo přístup k Divi Cloud.
Jdu si přidat novou sekci. Vyberu možnost přidat z Library. Přihlásím se. A po přihlášení mám na výběr i moji sekci, z předešlé stránky. Sekci vyberu a použiji ji na stránce. A tadááá. Mám zde nyní stejnou sekci na obou stránkách. Jednoduché a krásné.
Doufám, se vám tento článek líbil, pokud ano dejte mi o tom vědět. Loučí se s vámi lektor Jaro. A vidíme se možná i v nějakém mém kurzu. Čaute.

Vzdělávání
20.06.2022
Marián Kristeľ
14 nejpoužívanějších příkazu v GitHub a GitLab
Vývoj softwaru a programování je o psaní kódu a čím více programátorů pracuje na jednom projektu, tím je správa kódu náročnější. Sledování změn a jejich slučování by bylo náročné, pokud bychom neměli k dispozici nástroje, které nám v tom pomáhají. Proto v tomto momentě přichází na scénu verzování a správa zdrojového kódu.
Git je systém správy verzí pro správu zdrojového kódu, který jej sleduje s mnoha možnostmi. Vytvořil jej Linus Torvalds, známý zejména jako otec Linuxu. Git lze používat přes příkazový řádek nebo si nainstalovat nějaké GUI pro Git. S verzovacím systémem se můžete kdykoli vrátit k původní stabilní verzi a revertovat nepovedené změny, aniž byste o svůj kód přišli. Git se hojně využívá v mnoha oborech, od softwarového inženýrství až po kurzy jako social media marketing kurz nebo python kurz online, kde studenti potřebují uchovávat své kódy v pořádku.
Základní Git příkazyNež začnete používat Git příkazy, je třeba se přesunout do adresáře, ve kterém je projekt, který chcete verziovat.
• Git Init
Je to první příkaz, který je třeba spustit při zakládání nového projektu. Tento příkaz vytvoří adresář .git, do kterého bude Git ukládat všechny informace o repozitáři.
git init [názov repozitára]• Git Clone
Stáhne repozitář z GitHubu nebo GitLabu, v případě, že nemáte nastaveny SSH klíče, bude vyžadováno přihlášení.
git clone [URL]• Git Config
Před prvním commitem je dobré říci Gitu, kdo jste. Toto je obzvláště důležité, když pracujete v týmu, aby každý člen mohl identifikovat, kdo učinil konkrétní commit:
git config --global user.name ‘TvojUserName’git config --global user.email ‘TvojEmail’• Git Add
V Gitu mohou být soubory v jednom z následujících tří stavů: Modified, Staged, Committed. Pokud jste připraveni předat soubory, které jste upravili, můžete je přidat do stagingu pomocí příkazu:
git add [názov súboru]• Git Remove
Tento příkaz se používá k odstranění souboru z GitHubu bez jeho odstranění ve vašem lokálním repozitáři.
git rm [názov_súboru]
git rm -r [názov_súboru]• Git Commit
Příkaz uloží změny ze stagingu, do popisu commitu se dává krátká zpráva, například stručný popis nové funkcionality nebo fix bugu.
git commit -m “popis commitu”
git commit -a• Git Pull
Tímto příkazem stáhnete všechny změny ze vzdáleného repozitáře do vašeho lokálního pracovního adresáře.
git pull
git pull [názov_branche]
git pull orgin [názov_branche]• Git Push
Příkaz k odeslání potvrzených souborů do vzdáleného repozitáře.
git push -u origin masterTento příkaz se používá k odeslání potvrzených souborů do vzdáleného úložiště. Tento příkaz můžete použít k odeslání souborů do vzdáleného repozitáře až po prvním pushnutí souborů.
git push• Git Reset
Příkaz odebere soubor ze stagingu, vyresetuje necommitnutý soubor.
git reset [názov_súboru]• Git Status
Zobrazí všechny změněné soubory, zelenou barvou se ukáží ty, které jsou již ve stagingu, a červenou budou ty, které na stagingu ještě nejsou.
git status• Git Branch
git branchTento příkaz zobrazí seznam větví (branches). Chcete-li vytvořit novou větev, použijte příkaz:
git branch [názov_branche]• Git Diff
Příkaz ukáže rozdíly mezi soubory, které ještě nejsou commitnuty. Když chcete rychle vidět rozdíl mezi vaší aktuální větví a jinou větví, použijete příkaz:
git diffChcete-li porovnat dvě větve, použijete příkaz:
git diff branch1..branch2• Git Checkout
Příkaz git checkout se používá k přepínání mezi větvemi v repozitáři. Funguje na souborech, commitech a větvích.
git checkout• Git Merge
Když skončíte s vývojem ve své větvi a otestujete svůj kód, můžete sloučit svou větev s hlavní větví. Může to být vývojová větev nebo master větev, v závislosti na pracovním postupu.
git checkout develop
git pull
git merge feature1ShrnutíV tomto článku jsme vám přiblížili nejpoužívanější Git příkazy, vhodné zejména pro vývojáře. Co je to Git a jak funguje správa verzí, se hodí znát nejen při vývoji softwaru, ale i při studiu v různých rekvalifikačních kurzech, například v kurzech programování nebo it kurzech. Pro Git je k dispozici několik dalších příkazů, avšak výše zmíněné jsou ty nejvíce používané. Pokud ve své práci používáte často i jiné příkazy, neváhejte se o ně podělit v komentářích.

Vzdělávání
10.06.2022
Marián Kristeľ
Rozdíly mezi Universal Analytics a Google Analytics 4
Konec Universal Analytics se blíží, Google oznámil konec používání od 1. července 2023 a k dispozici budou jen Google Analytics 4. V tomto článku si vysvětlíme, co je Google Analytics 4, jak funguje a jaké novinky přináší.
Implementace Google Analytics 4 na webNejprve vytvořte vlastnictví pro Google Analytics 4 a následně přejděte na nastavení Data Streamu (Streamy dat). Jedná se o datový tok, zdroj dat, která budou z vašeho webu nebo mobilní aplikace směřovat do Google Analytics 4. Data streamů v jednom Google Analytics 4 vlastnictví může být několik. Každý data stream má vlastní identifikátor. Vytvoření data stremu je poměrně jednoduché, stačí napsat url vašeho webu, jméno streamu a klepnout Vytvořit stream. Rozšířená měření nechte zapnutá všechna.[Nastavení streamu dat v GA4]Pro další nastavení data streamu si jen zkopírujte Identifikátor měření (Measurement ID) a v Google Tag Manager vytvořte nový tag (značku) GA4 Configuration. Vložíte Identifikátor měření a jako spouštěč (trigger) nastavte All pages. Uložte a vypublikujte změny. Základní nastavení tak máte hotová a Google Analytics se zanedlouho začnou plnit daty.
Rozdílný datový model Data model v Universal Analytics je založen na Relacích (Sessions) a Zobrazení stránek (Pageviews). Data model v Google Analytics 4 je založen na událostech (events) a parametrech. Universal Analytics využíval schéma uživatel - návštěvy - zobrazení stránky, reportování však bylo postaveno primárně na datech v rámci sessions. Jedna návštěva byla neunikátní a v nastavení Google Analytics trvala 30 minut. Po jejím uplynutí začíná nová návštěva, a to není vůbec přesné.
V Google Analytics 4 je model založen na parametrech a eventech a také 'pageview' je považován za event. Tyto eventy tedy dokážou poskytnout mnohem detailnější informace o tom, co uživatelé dělají na webu či v aplikaci. Kromě automaticky sbíraných nebo doporučených událostí si umíte vytvořit vlastní. Nastavování eventov byste měli zvládnout i v samotném rozhraní Google Analytics 4, ovšem určitě budete muset využít i Google Tag Manager.
Nastavování cílů a konverzeNastování cílů v Google Analytics 4 je jednoduché, zvolíte některý z vytvořených eventov a kliknete na možnost "Mark as conversion". Při nastavení e-commerce doporučujeme využít implementaci přes Google Tag Manager podle specifikace od Google.
Usnadnění práce s daty v Google Analytics 4Pokud jste zvyklí na Universal Analytics a načtete Google Analytics 4, můžete být mírně překvapeni z prostředí. Nejsou zde žádné tabulky a čísla, ale uživatel si umí vše nastavit a je na jeho volbě, jestli bude zobrazovat tabulky, grafy a pod.
Dobrou zprávou je také spolupráce s BigQuery. Funkcionalita vhodnější pro velké firmy, ale prozatím je export do BigQuery bez omezení či limitů.
V Google Analytics 4 si můžete zvolit ze 4 různých atribučních modelů, které chcete v rámci reportů použít. Vytváření publík je také velmi jednoduché, podobně jako u Universal Analytics se publika budují na základě podmínek. Publika lze také kopírovat, funkcionalita, kterou ocení nejeden PPC specialista.
ShrnutíStále nejde o finální verzi Google Analytics 4, je možné, že zajímavá nová funkcionalita ještě přibude. Čím dříve GA 4 nasadíte na váš web či do aplikace, tím dříve získáte data pro vyhodnocování. GA 4 a Universal Analytics můžete používat také současně. Nové Google Analytics 4 přinášejí jiný a detailnější pohled na webovou analytiku, měli byste se s nimi naučit pracovat co nejdříve.

Vzdělávání
18.04.2022
Marián Kristeľ
Novinky ve Photoshopu 2022
V tomto článku se podíváme na několik novinek, které přinesl Photoshop 2022. Představíme jen ty podle nás nejzásadnější změny, jelikož změn v této verzi Photoshopu bylo více.
Výběr objektů (Object selection tool)Tento nástroj aktuálně funguje mnohem více automaticky a pomáhá při rychlém vymaskování. Stačí kurzorem přejet přes objekt a hned uvidíte zvýrazněnou masku. Po kliknutí na objekt se vytvoří výběr, se kterým můžete pracovat. Funkce má stále co vylepšovat se svojí Sensei AI, určitě se tedy nevyhnete následné úpravě a upřesnění masky, ale celkově jsou výsledky na dostačující úrovni.[Object finder a Object selection tool]
Neural Filter
Funkce Neural Filters byla vydána již v loňském roce, nicméně v této verzi Photoshopu přichází optimalizovanější a také se zapracováním 3 novinek:
• Kombinátor krajin (Landscape mixer): vytvořte novou krajinu smícháním různých obrázků krajiny dohromady. Umíte změnit roční období, denní dobu a přidat další úpravy.
• Přenos barev: můžete přizpůsobit barevný tón na fotografii pomocí úplně jiného obrázku.
• Harmonizace: tato funkce smíchá dva obrázky a automaticky upraví tón a osvětlení tak, aby výsledný obrázek působil maximálně přirozeně a bez barevných nerovnoměrností.
[Neural filtre]
Přidávání komentářů
Vhodné pro grafiky pracující v týmu. Jednoduše pomocí této funkce komentujte grafiku, na které aktuálně pracujete. Grafické práce, na kterých pracujete, si uložíte do Creative Cloudu, zasdílíte a můžete komentovat a dostávat komentáře.
Vkládání vektorů jako vrstvy
Vylepšená interoperabilita mezi oblíbenými Adobe aplikacemi Photoshop a Illustrator umožňuje snadné přenášení souborů Illustratoru s vrstvami, vektory a vektorovými maskami do Photoshopu, kde je můžete dále upravovat.
Možnost Vložit jako > Vrstvy představuje nové vylepšení spolupráce mezi Illustratorem a Photoshopem, které doplňuje stávající možnosti Inteligentní objekt, Obrazové body, Cesta a Vrstva tvaru. Tato nová možnost podporuje import vrstev Illustratoru při zachování jejich vizuální a funkční účinnosti a struktury vrstev.[Prepojenie Photoshopu a Illustratoru]
Plná podpora formátu WebP
Soubory WebP lze ve verzi Photoshop 2022 otevírat, vytvářet, upravovat a ukládat bez potřeby použití pluginů nebo nastavení předvoleb. Chcete-li otevřít WebP soubor, udělejte tak jako s jakýmkoli jiným souborem. Po dokončení úprav dokumentu otevřete dialog Uložit jako nebo Uložit kopii a uložte soubor WebP.
Dalšími výraznými novinkami, které však nebudeme podrobně popisovat, je vylepšení iPad aplikace Photoshopu nebo webové verze Photoshopu (Photoshop on the web).
Které novinky ve verzi Photoshop 2022 zaujaly nejvíc vás?

Vzdělávání
28.02.2022
Skillmea
K čemu se používá Kotlin?
Kotlin je programovací jazyk, který v roce 2011 vydala společnost JetBrains, která prodává integrovaná vývojová prostředí (IDE) pro různé programovací jazyky. Od té doby se stal oblíbeným jazykem vývojářů a nahradil Javu v mnoha softwarových projektech.
V tomto článku se podíváme na to, proč se Kotlin stal populárním, jaké jsou jeho výhody ak čemu se používá.
Výhody programovacího jazyka Kotlin
Vznik Kotlinu začal tehdy, když vedoucí vývojář Dmitrij Jemerov hledal funkce, které nemohl nalézt v Javě. Scala, další programovací jazyk, který běží na Java Virtual Machine (JVM), byl blízko tomu, co chtěl, ale jeho kompilace trvala příliš dlouho.
Jemerův chtěl jazyk, který má všechny funkce modernějších programovacích jazyků, běží na JVM a kompiluje se stejně rychle jako Java. Tak si vytvořil svůj vlastní jazyk – Kotlin.
Kotlin byl navržen jako náhrada za Javu na operačním systému Android. Osm let po vydání, v roce 2019, Google konečně souhlasil s Jemerovem a většinou Android developerů a oznámil, že Kotlin je preferovaný jazyk pro vývoj Android aplikací.
Zde je několik důvodů, proč vývojáři upřednostňují Kotlin před Javou:
• Kotlin je stručný a šetří čas, který byste jinak strávili psaním standardního kódu v Javě. Kotlin umí ušetřit stovky řádků kódu v porovnání s Javou.
• Jevovský soubor můžete převést na Kotlin soubor pouze pomocí skriptu. Kotlin a Java mohou spolu fungovat na jednom projektu bez problémů.
• Kotlin má velkou komunitu. Pokud se někdy zaseknete, na různých fórech a sociálních sítích můžete snadno najít jiné vývojáře, kteří vám pomohou.
• Kotlin zefektivňuje asynchronní programování. Asynchronní uskutečňování síťových a databázových volání v jazyce Java je nemotorné a bolestivé. Kotlin má korutiny (coroutines), díky kterým je asynchronní programování snadné a efektivní.
• Kotlin řeší hodnoty null. Hodnota null v Javě může způsobit selhání programu, pokud na to nejste připraveni. V Kotlině můžete k proměnným, které mohou mít hodnotu null, přidat jednoduchý operátor, abyste předešli těmto problémům.
• Kotlin může běžet na více platformách. Kotlin může běžet kdekoli běží Java, takže jej můžete použít k vytváření aplikací pro různé platformy.
• Přechod na Kotlin je jednoduchý. Kotlin je plně kompatibilní s Javou, takže nemusíte měnit celý kód najednou. Aplikaci můžete pomalu migrovat, abyste mohli používat Kotlin.
K čemu se Kotlin používá?
Kotlin je navržen tak, aby běžel na Java Virtual Machine a může simultánně s Javou. Přestože Kotlin poprvé začal jako jazyk speciálně pro vývoj Android aplikací, rychle se rozšířil v komunitě Java programátorů díky svým funkcím a od té doby se používá pro mnoho typů aplikací.
Android development
Jak jsme již zmínili, Kotlin je preferovaný jazyk pro vývoj Android aplikací, neboť umožňuje vývojářům psát stručnější, výraznější a bezpečnější kód. Oficiální IDE pro vývoj pro Android, Android Studio, Kotlin zcela podporuje, takže můžete získat stejný typ dokončování kódu a kontroly typu, který vám pomůže psát kód Kotlin jako v případě Javy.
Mít mobilní aplikace nebo vysoce optimalizované weby je v současnosti nezbytnou podmínkou mnoha firem, neboť většina lidí v současnosti přistupuje na internet prostřednictvím mobilních telefonů. Android má více než 70% podíl na trhu mobilních telefonů, takže i kdyby byl Kotlin určen pouze pro vývoj Android aplikací, Kotlin vývojáři by byli velmi žádaní. Přesto lze Kotlin použít na mnohem více.
Backend web development
Mnoho back-endového vývoje se provádí v Javě pomocí frameworků jako např. Spring. Kotlin však pronikl také do vývoje webu na straně serveru, protože s ním bylo pro vývojáře mnohem snazší pracovat.
Moderní funkce jazyka umožňují webovým vývojářům vytvářet aplikace, které lze rychle škálovat na běžně dostupném hardwaru. Jelikož Kotlin je interoperabilní s Javou, můžete pomalu migrovat aplikaci tak, aby používala Kotlin jeden soubor po druhém, zatímco zbytek aplikace stále používá Javu.
Kotlin funguje i se Springem a jinými frameworky, takže přechod na Kotlin neznamená, že musíte změnit všechno, na co jste zvyklí. Google, Amazon a mnohé další společnosti již pomalu nahrazují Javu za Kotlin.
Fullstack web development
Kotlin se používá také na server-side vývoj. Samotná Java se k tomu používá v podstatě od svého vzniku. Kotlin však můžete použít i pro vývoj frontendu pomocí Kotlin/JS.
Kotlin/JS umožňuje vývojářům přistupovat k výkonným browserovým a webovým API rozhraním typově bezpečným způsobem. Fullstack vývojářům tak stačí znát Kotlin. Mohou psát frontend ve stejném jazyce, jaký použili pro backend, a bude zkompilován do JavaScriptu, aby se spustil v prohlížeči.
Data Science
Datoví vědci používali také Javu pro zjišťování čísel, zjišťování trendů a predikce – takže dává smysl i to, že Kotlin najde své uplatnění ve světě data science.
Datoví vědci mohou používat všechny standardní Java knihovny, které používaly pro Java projekty, ale budou psát svůj vlastní kód v Kotlině. Jupyter a Zeppelin, dva nástroje, které denně používají mnozí datoví vědci k vizualizaci údajů a průzkumný výzkum, také podporují Kotlin.
Multiplatformní vývoj mobilních aplikací
Multiplatformní vývoj pro mobily v Kotlině je určen jako softwarový vývojový kit pro vytváření multiplatformových mobilních aplikací. To znamená, že s jedním Kotlin kódem budete moci vytvářet aplikace, které fungují nejen na telefonech s Android operačním systémem, ale také na iPhone telefonech či Apple Watch.
Závěr
Kotlin je moderní programovací jazyk, který může běžet souběžně s Javou a zároveň se snáze píše. Pokud chcete vyvíjet aplikace pro Android nebo multiplatformní aplikace s JVM, můžete to udělat rychleji a jednodušeji s Kotlinem než s Javou.
Chtěli byste se o Kotlině dozvědět více? Náš online kurz Kotlin pro začátečníky je vhodný, pokud s vývojem samotným nebo vývojem v jazyce Kotlin teprve začínáte. Kurz vás naučí základní koncepty programování a naučí vás základy programování v Kotlině.

Vzdělávání
06.02.2022
Skillmea
Co je to a jak se rýchlo naučiť programovací jazyk Python
Pokud čtete tento článek, pravděpodobně to znamená, že jste se rozhodli nebo se rozhodujete zahájit novú kariéru a chcete se stát Python programátorem/kou.
Záměrem tohoto návodu je poskytnout vám představu o ekosystému programovacího jazyka Python a pomoci vám při učení. Upozorňujeme, že níže uvedený seznam je dosti komplexní a položky nejsou uvedeny v přesném pořadí. Nemusíte se učit vše, co je uvedeno v článku. Nicméně vědět, co nevíte, je stejně důležité jako vědět (něco) dělat. 🙃
Tento článek se pokusí dát vám odpovědi na většinu otázek o kariéře developera. Než začneme, podívejme se, proč byste se měli naučit tento programovací jazyk.
Proč se učit Python?
Python získal prestižní ocenění TIOBE Programming Language of the Year za rok 2021. Pokud jste dosud o TIOBE indexu neslyšeli, jedná se o indikátor popularity programovacích jazyků. Index se aktualizuje jednou za měsíc. Hodnocení jsou založena na počtu vývojářů v daném jazyce na celém světě, kurzů a také poskytovatelů třetích stran. K výpočtu hodnocení se používají oblíbené vyhledávače jako Google, Bing, Yahoo!, dále Wikipedia, Amazon, YouTube a Baidu. Index TIOBE v žádném případě není o nejlepším programovacím jazyce nebo jazyce, ve kterém bylo napsáno nejvíce řádků kódu.
Je skvělý jak pro začátečníky v programování, tak pro zkušené programátory. Navrhl Guido van Rossum a poprvé se objevil v roce 1991. Pokud jste úplní začátečníci, Python se umíte naučit velmi rychle. Psaní kódu je podobné běžnému psaní. Začátečnickou programátorskou větu "Hello World" v něm napíšete jen pomocí jednoho řádku kódu: Pro začínající programátory je tedy i kvůli přehlednosti kódu Python velmi doporučen. Dalšími faktory jsou rostoucí popularita jazyka a komunita a využitelnost jazyka v mnoha oblastech. Je to open source, a co je možná důležitější, multiplatformový jazyk, což znamená, že jej lze spustit na Macu, Windows, Linuxu a Raspberry Pi.
Ať už jste v programování úplní nováčci nebo máte za sebou zkušenosti, Python nabízí flexibilitu a jednoduchost, kterou ocení každý vývojář. Pokud hledáte vzdělávací kurzy nebo konkrétní Python kurz online, existuje mnoho zdrojů, které vám pomohou začít. Python je také často součástí IT kurzů, které se zaměřují na programování a vývoj softwaru.[Image]
K čemu se používá programovací jazyk Python?
Na rozdíl od HTML, CSS a JavaScriptu, které jsou považovány za stavební bloky internetu, Python je univerzální programovací jazyk, což znamená, že jej lze použít nejen pro vývoj webu, ale také pro vývoj softwaru, psaní systémových skriptů a v neposlední řadě pro data science.
Jak jsme již zmínili výše, vytvořil ho Guido van Rossum v roce 1991 a jeho záměrem bylo pomoci vývojářům psát jasný, logický kód a tato filozofie z něj učinila jeden z nejpopulárnějších programovacích jazyků.
Verze Pythonu 2.0 přenesla jazyk do jeho moderní podoby na začátku 21. století. Ve své podstatě však zůstává stejný. Pythonovský kód používá objektově orientované paradigma, takže je obvykle výbornou volbou pro velké projekty i menší programy.
Index balíků Python (PyPi) zobrazuje tisíce modulů třetích stran. Pojďme si trochu blíže posvítit na využití Pythonu pro jednotlivá odvětví.
Webové aplikace
Role při web developmentu může zahrnovat odesílání údajů na servery a ze serverů, zpracování dat a komunikaci s databázemi, směrování URL a zajištění bezpečnosti. Nabízí několik frameworků vhodných pro webový vývoj. Mezi nejvíce používané patří Django a Flask.
Na internetu existují tisíce webových stránek vytvořených v Pythonu. Mnoho současných technologických společností si volí ho jako back-end platformu pro své weby. Například Instagram používá Python na backendu, stejně tak Google ho využívá ve svém tech stacku.
Webstránka streamovací služby Spotify je postavena na WordPressu, Spotify aplikace je vyrobena s použitím Pythonu. Backend Spotify sestává z mnoha vzájemně závislých služeb, které jsou propojeny vlastním protokolem zpráv přes ZeroMQ. Přibližně 80 % těchto služeb je napsáno v jazyce v tomto jazyce.
Dalšími velkými webovými službami používajícími Python jsou Netflix, Uber, Dropbox nebo Pinterest. Jedná se o velké weby s miliony uživatelů. Proč tedy nepoužít Python i na tvůj projekt?
Datová analýza a machine learning
Python se v současnosti využívá ke zpracování velkého množství dat, datové analýzy, machine learningu či deep learningu. Python se stal standardem ve světě data science, což umožňuje analytikům a jiným odborníkům používat jazyk k provádění složitých statistických výpočtů, vytváření vizualizací údajů, vytváření algoritmů strojního učení, manipulaci a analýzu údajů a provádění dalších úkolů souvisejících s daty.
Python má také řadu knihoven, které umožňují programátorům psát programy pro analýzu dat a strojní učení rychleji a efektivněji, jako například TensorFlow aa Keras. Více o tomto tématu si přečtěte v našem článku o nástrojích pro dátovú analýzu.
Testování softwaru a prototypování
Při vývoji softwaru může Python pomáhat při úkolech, jako je sledování chyb a testování. Pomocí Pythonu mohou vývojáři automatizovat testování nových produktů nebo funkcí. Populární nástroje pro testování softwaru zahrnují Robot framework, Pytest či Nose2.
Velmi silnou stránkou Pythonu je také možnost rychlého prototypování. Umíte si ověřit, zda váš nápad funguje v Pythonu. Implementace je možná iv jiném jazyce, pokud je k tomu vhodnější.
Automatizace a scriptování
Pokud zjistíte, že vykonáváte nějaký úkol znovu a znovu, můžete pracovat efektivněji, pokud ji zautomatizujete pomocí Pythonu. Psaní kódu používaného k vytváření těchto automatizovaných procesů se nazývá skriptování. Ve světě programování lze automatizaci použít ke kontrole chyb, konverzi souborů, provádění jednoduché matematiky a odstraňování duplikátů v údajích.
Python mohou dokonce používat i relativní začátečníci k automatizaci jednoduchých úkolů na počítači, jako je vyhledávání a stahování online obsahu (web scraping), sledování akciových trhů a cen kryptomen nebo odesílání e-mailů a textů v požadovaných intervalech.[Image]
Co potřebuje vědět Python developer?
Python se může jevit jako jednoduchý jazyk, ale má různé komponenty a prvky. Abyste se dostali na správnou cestu, měli byste vědět, čemu dát při učení přednost. Pokud se tedy chcete stát Python developerem/kou, potřebujete získat některé dovednosti. Pojďme se podívat, které to jsou.
Python
Je to logické. K tomu, abyste se stali Python vývojářem, budete muset ovládat programovací jazyk Python. Na začátek se budete muset naučit základní pojmy v Pythonu, včetně objektově orientovaného programování, základní syntaxe Pythonu, sémantiky, primitivních datových typů a aritmetických operátorů. Python byl navržen pro čitelnost a má určité podobnosti s anglickým jazykem s vlivem matematiky.
Python knihovny
Jako open source komunitní programovací jazyk má Python k dispozici širokou škálu knihoven a jejich používání vám může zjednodušit život a práci Python developera. Různé projekty budou vyžadovat různé knihovny, ale je dobré se seznámit s některými z nejběžnějších včetně Pandas, NumPy, Matplotlib či Scikit-Learn. Python ekosystém obsahuje aktuálně více než 137 000 knihoven.
Python frameworky
Abyste se stali dobrým a efektivním Python programátorem, budete se muset seznámit s Python frameworky. Podobně jako výše uvedené knihovny, to, s čím budete pracovat, bude záviset na vašem konkrétním projektu.
Frameworky vám pomohou dokončit úkol s menším počtem řádků kódu, urychlí vaše pracovní úkoly a postarají se o triviální záležitosti. Primárně existují tři typy Python frameworků: full-stack, mikro a asynchronní frameworky.
Asi nejpopulárnějším full-stack frameworkem je Django, využívané zejména pro vývoj webových aplikací. Mezi mikroframeworky je populární Flask, který je díky svému modulárnímu designu snadno přizpůsobitelný. Asynchronní framework AIOHTTP je framework, který se ve velké míře spoléhá na funkce Pythonu 3.5+, jako jsou async a waits
ORM knihovny
Pro Python developery je také mimořádně užitečné znát Object Relational Mapper (ORM) knihovny, jako jsou SQLAlchemy nebo Django ORM, které mohou pomoci při konvertování údajů mezi nekompatibilními systémy.
ORM knihovny poskytují vysokoúrovňovou abstrakci relační databáze, což umožňuje vývojářům psát Python kód namísto SQL k vytváření, aktualizaci, čtení a odstraňování údajů a schémat v jejich databázi.
Python programátor by měl mít základní znalosti o ORM knihovně jako SQL, protože ORM knihovny zefektivňují a zrychlují práci.
Front-end technologie
Python developeři často pracují na vývoji na straně serveru (backend), ale jako součást vývojářského týmu mnoho Python developerů pomáhá i frontendistům a musí tedy spolupracovat s front-end týmem.
Technologie jako HTML5, CSS3 a JavaScript/jQuery nejsou nezbytností pro Python vývojáře. Avšak pokud můžete, pokuste se o ně získat základní znalosti a oni vám umožní pochopit, jak věci fungují a co lze pomocí nich vytvořit. Jejich znalost vám pomůže lépe pochopit uživatelské rozhraní a vizuální estetiku aplikací.
Verzování
Vývojáři se každý den zabývají obrovským množstvím dat, různými verzemi kódu. Proto vám znalost v softwaru pro správu verzí, jako je Git pomůže udržet si pořádek a efektivitu. Chcete-li implementovat kontrolu verzí kódu, měli byste se naučit používat i GitHub a jeho pojmy jako push, pull, fork a commit.
Testování
Žádný vývojář není dokonalý, všichni děláme chyby. Testování kódu pomáhá zachytit tyto chyby nebo se vyhnout jejich implementaci do produkce. Testování je proto při vývoji softwaru velmi důležité. Populární frameworky a knihovny pro testování pythonovského kódu jsou Pytest, Robot framework, PyUnit či Nose2.
Závěr
Chcete-li se stát Python programátorem, musíte umět programovat. Pokud budete postupovat podle výše uvedené kariérní cesty, jste na cestě k úspěchu. Vždy se rozvíjejte a snažte se dozvědět o nových knihovnách a frameworkech.
Jako začátečník na nic nečekejte a zkuste něco v Pythonu napsat. Doporučujeme malé hry, které jsou jednoduché, jejich rozsah je malý a začátečník je dokáže dokončit. Takže začněte s malými věcmi a nedělejte se dělat chyby.
Neomezujte své znalosti na teorii, místo toho je implementujte co nejdříve do praxe. Pracujte na vlastních projektech a vytvořte zajímavé portfolio. Při dodržení tohoto všeho vás žádná překážka nemůže zastavit v tom, abyste se stali Python developerem. Držíme palce 🤞

Vzdělávání
28.01.2022
Skillmea
Co je Spring framework a jak začít
Spring usnadňuje vývoj enterprise aplikací, což jej činí první volbou u projektů libovolné velikosti. Vývoj Springu začal, když bylo velmi komplikované vyvíjet enterprise aplikace v enterprise edici Javy. Tvůrci Springu toto využili a vytvořili nástroj, který je vysoce používaný.
Domovská stránka je http://spring.io/.
V sekci projects uvidíš, že Spring obsahuje spoustu projektů. Jako například Spring Boot, který nám zjednodušuje práci se Springem. Spring Framework - je projekt, který obsahuje základní core funkce. Projektů je mnoho a každý se soustřeďuje na nějakou oblast vývoje aplikací.
ZačínámePokud ses rozhodl učit se Spring, tak jako první si vytvoříme základní projekt, který bude obsahovat závislosti, které budeme používat. Navštivme stránku https://start.spring.io/, na které najdeme spring initializr. Tímto způsobem si vyklikáme, jaké závislosti potřebujeme a initializr nám vytvoří strukturu projektu. Samozřejmě lze v průběhu vývoje různé závislosti měnit.
Vyplníme group a artifact, podle toho, jak si zvyklý používat balíky. Vpravo máme tlačítko ADD DEPENDENCIES, na které klikneme:[Image]Pokud ses rozhodl vyvíjet webovou aplikaci, tak si vyber potřebné závislosti, to vše závisí na tom, co jdeš dělat. Já jsem se rozhodl, že jdu dělat webovou aplikaci, která bude používat Hibernate a databázi budu mít v paměti.
Zaklikni:
• Spring Web – budeme vyvíjet webová aplikaci[Image]
• JPA – objekty budeme mapovat na databázi
[Image]
• H2 – jako databázi budeme používat H2 databázi, pro kterou nepotřebujeme instalovat databázový server, neboť pracuje v paměti
[Image]
• Actuator – monitorování aplikace
[Image]
Nyní dáme vygenerovat projekt. Vygeneruje se nám zip soubor, jehož obsah vyextrahuj na místo, kde chceš, aby byl tvůj projekt umístěn. Tento soubor nyní otevřeme v IDEi.[Image]
Otevření projektu
Otevřeme si vývojové prostředí a dáme otevřít projekt ze zdrojového kódu a vybereme námi vygenerovaný projekt. Na pozadí se budou stahovat závislosti, tak musíš chvíli počkat.
Maven
Pokud jsme například zvolili web, tak máme v pom.xml souboru web starter. Když se tato dependency stáhne, tak má v sobě také pomko a také dependency, které se nám stáhnou také. Tedy na to, abychom rozjeli všechny dependency, které jsou potřebné pro spring web, nemusíme je dávat do našeho pomka sami – tyto závislosti se nám stáhnou automaticky, protože jsme je zdědili.
Pokud chceme pracovat s knihovnou Hibernate, tak ji nezadáváme do pomka, ale místo toho tam máme starter jpa a tento nám přitáhne i Hibernate.
Takže na pozadí se děje spousta věcí, které sami nevidíme.
Závěr
Nyní jsi připraven skočit do vývoje Spring aplikací a učit se, učit se, učit se. Pokud se při něčem zasekneš, zkus podívat naše online kurzy Spring framework nebo Spring Boot.
.jpg)
Vzdělávání
15.01.2022
Skillmea
Video editor pro kvalitní reels. Porovnejte DaVinci resolve vs. Finalcut Pro
DaVinci Resolve je dobře známý jako robustní platforma pro color grading a korekci barev. Zatímco Premiere Pro je vysoce respektovaný NLE editor (non-linear editor). Premiere Pro je také plně integrován s dalším softwarem Creative Cloud od Adobe, včetně Photoshopu, Illustratoru, Audition a nejvíce s After Effects. Dalším hráčem na trhu editování a tvorby videa je Final Cut Pro, nabízený společností Apple.
Final Cut Pro, Adobe Premiere Pro a stále populárnější DaVinci Resolve soupeří o pozornost dnešních video editorů. Podívejme se na výhody a nevýhody jednotlivých programů a sami se rozhodněte, jak každý z nich ovlivní váš pracovní workflow a přispěje ke zvýšení produktivity.
🌍 Celkový přehled
Začněme všeobecným pohledem na každou platformu a na to, co ji odlišuje od ostatních.
DaVinci Resolve
Firma Blackmagic Design přeměnila DaVinci Resolve z aplikace na color grading na výkonnou aplikaci pro postprodukci videa. Resolve spojuje rychlost Final Cut se známými konvencemi Premiere Pro. Stránky Cut a Edit vám umožňují zvolit si svůj přístup k úpravám. Dokonce přidali externí hardware, aby do procesu střihu vnesli tradiční pocit „pásky“.
Následuje grafika založená na nodech, efekty a třídění barev. Barevné nástroje DaVinci Resolve jsou vysoko nad konkurencí a přinášejí opravdu vynikající výsledky. Zvuk Fairlight dává editorům možnost pracovat na svém zvuku přímo v aplikaci.
Final Cut Pro
S Final Cut Pro X nabízí Apple nejneortodoxnější řešení v této skupině programů. Apple ve svém přístupu k úpravám považuje video za „údaje“ a ne za „filmové klipy“. Nástroje pro organizaci, klíčová slova a protokolování umožňují editorům efektivně a rychle organizovat obrovská množství záznamu.
Magnetická časová osa zdůrazňuje spíše vztahy mezi klipy než celkovou časovou osu a efektivně pracuje na zefektivnění každého kroku procesu. Final Cut Pro je rovněž neustále optimalizován pro hardware Apple a rodinu kodeků ProRes. Výsledkem je editor, který se zaměřuje na metadata pro organizaci a rychlost ve střihu i exportu videa.
Pokud hledáte online vzdělávací kurzy, které vás naučí efektivně pracovat s těmito nástroji, existuje řada možností. Ti nejlepší video kurzy často zahrnují podrobné lekce na všechna tato řešení, což vám pomůže najít ten správný nástroj pro váš projekt.
Adobe Premiere Pro
Až do verze Final Cut Pro 7, Final Cut Pro a Premiere Pro zaujaly do značné míry podobný přístup k postprodukci. Když Apple radikálně změnil své editační paradigma s příchodem Final Cut Pro X, Adobe se zaměřil na editory, kteří změnu neuvítali.
V mnoha ohledech se společnost Adobe zaměřuje na to, aby byla nejběžnějším nástrojem. Známé koncepty, jako jsou koše a stopy, zkušení editoři velmi dobře znají. Ti, kteří pracují s VFX, milují dynamické propojení mezi Premiere Pro a After Effects, které umožňuje projektům přesouvat se mezi různými nástroji Adobe, aniž by je editoři museli exportovat nebo dekódovat.
Adobe také obsahuje silnou sadu výkonných zvukových nástrojů v balíku Creative Cloud s Adobe Audition, který pomáhá editorům vyladit zvuk do finální podoby, aniž by opustili ekosystém Adobe. Kromě toho na Premiere Pro naleznete více editorů než na jiných platformách, díky čemuž je skvělou volbou při spolupráci s jinými týmy, vzdělávání a řešení případných problémů.DaVinci Resolve.
[DaVinci Resolve]
🧩 Rozhraní (interface)
DaVinci Resolve
DaVinci Resolve používá free-form editor časové osy. Rozděluje je do více sekcí, aby bylo možné snáze najít a pochopit různé části úpravy videa. Bezplatná verze nabízí pět sekcí - Cut & Edit, Fusion, Color, Fairlight a Deliver. Fairlight je místo, kde můžete upravovat zvuk videa.
Final Cut Pro
Final Cut Pro využívá magnetickou časovou osu, která vše zjednodušuje do jedné stopy a efektivně organizuje. To poskytuje Final Cut Pro výhodu používání zjednodušené časové osy, která usnadňuje novým uživatelům úpravy videa. Nemůžete si ji však přizpůsobit podle svých představ, ale pomocí klipů můžete dělat všechno, jako je slučování, označování, přidávání grafiky a mnohé další.
Adobe Premiere Pro
Premiere Pro používá časovou osu tradičního nelineárního editoru (NLE) se stopami a hlavami stop. Obsah vaší časové osy se nazývá sekvence a pro lepší organizaci můžete mít vnořené sekvence, podsekvence a dílčí klipy. Časová osa obsahuje také karty pro různé sekvence, což může být užitečné, pokud pracujete s vnořenými sekvencemi.
Uživatelské rozhraní je mimořádně konfigurovatelné a umožňuje vám odpojit všechny panely. Můžete zobrazit nebo skrýt miniatury, průběhy, klíčové snímky. Existuje sedm předkonfigurovaných pracovních prostorů, včetně sestavy, úprav, barev a nadpisů.
💾 Organizace mediálních souborů
DaVinci Resolve
DaVinci Resolve udržuje věci organizované pomocí sekce vyhrazené pro přidávání médií. Karta Media vám umožňuje přidat jakákoli média, která můžete později použít ve videu. Může to být videoklip, obrázek, zvuk nebo cokoliv, co podporuje DaVinci Resolve.
Nemůžeme nezmínit dynamické složky, které skvěle fungují pro vyhledávání souborů a jejich třídění.
Final Cut Pro
Na druhé straně Final Cut Pro vám umožňuje snadno organizovat soubory. Obsahuje možnosti, jako jsou knihovny, události, role a označování klíčových slov při importu médií do Final Cut Pro. Knihovna je místo, kam importujete své soubory a média. Kromě toho, že je jen importujete, můžete klipy také přejmenovat v dávkách a sledovat je všechny na jednom místě.
Adobe Premiere Pro
Stejně jako tradiční NLE, Premiere Pro umožňuje ukládat související média do zásobníků, které jsou podobné složkám. Stejně jako v případě složek, můžete mít zásobníky v rámci zásobníků. Na položky můžete použít i barevné štítky, ale ne klíčová slova.
Panel Knihovny vám umožňuje sdílet prostředky mezi jinými aplikacemi Adobe, například Photoshop a After Effects.[Final Cut Pro X]
🔊 Audio
DaVinci Resolve
DaVinci Resolve přichází s Fairlight, který představuje významnou konkurenci tomu, co nabízí Final Cut Pro a Adobe Premiere Pro. Fairlight je aplikace zabudovaná do DaVinci Resolve a je k dispozici v samostatné sekci pro všechny potřeby úprav audia (zvuku). Avšak i na kartě Upravit (Edit) můžete provést několik základních úprav zvuku.
Fairlight poskytuje kompletní DAW (Digital Audio Workstation) pro úpravu zvuku s různými efekty, nahráváním, mícháním stop a mnoho dalších.
Final Cut Pro
Final Cut Pro vám umožňuje snadno používat zvuk na časové ose. Ve srovnání s DaVinci Resolve je to nejdůležitější bod Final Cut Pro. Dodává se s širokou škálou bezplatných (royalty-free) audio stop, které můžete použít na své časové ose bez obav z porušování autorských práv. Navíc, když importujete zvuk do Final Cut Pro, automaticky se odstraní většina hluku na pozadí.
To znamená, že si můžete vybrat iz rozsáhlé knihovny doplňků, abyste věci dělali rychleji. A co se týká důležitých funkcí, můžete stříhat, mixovat, spojovat a dokonce použít doplněk Apple Logic Pro k získání efektu prostorového zvuku ve vaší audio stopě.
Adobe Premiere Pro
Audio Mixer v Premiere Pro zobrazuje vyvážení, jednotky hlasitosti (VU), indikátory oříznutí a ztlumení/sólo pro všechny stopy časové osy. Můžete jej použít k úpravám během přehrávání projektu. Nové stopy se automaticky vytvoří, když pustíte zvukový klip na časosou osu a můžete určit typy jako Standard, Mono, Stereo, 5.1 a Adaptive.
Máte-li nainstalován Adobe Audition (aplikace v Creative Cloud), můžete mezi ním a Premiere Pro přepínat zvuk a využívat pokročilé techniky, jako je adaptivní redukce šumu, parametrický ekvalizér, automatické odstranění kliknutí, studiový reverb a komprese.
🎨 Color grading
DaVinci Resolve
Pokud jde o color grading, DaVinci Resolve je absolutní špička. Pokud se víc zajímáte právě o barvení videa, DaVinci Resolve může být pro vás ideálním nástrojem. Nabízí širokou škálu rozsáhlých a pokročilých nástrojů pro úpravu barev. DaVinci Resolve původně začal jako nástroj pro korekci barev, takže je jistě nejlepší ve své třídě.
Final Cut Pro
Final Cut Pro přichází se sadou nástrojů pro korekci barev a color grading. Patří mezi ně sada nástrojů, jako jsou křivky, LUT, barevná kolečka a mnoho dalších presetů. Dokonce ani s těmito funkcemi se třídění barev ve Final Cut Pro nepřibližuje tomu, co nabízí DaVinci Resolve.
Adobe Premiere Pro
Premiere Pro obsahuje nástroje Lumetri Color. Jsou to funkce pro profesionální color grading, které dříve existovaly v samostatné aplikaci SpeedGrade. Nástroje Lumetri podporují 3D vyhledávací tabulky (LUT) pro výkonný a přizpůsobitelný vzhled. Nástroje nabízejí pozoruhodné množství manipulace s barvami spolu s velkým výběrem vzhledu filmu a HDR. K dispozici jsou také předvolby úprav Sytost, Vibrance, Faded Film a Sharpen. Nejpůsobivější jsou možnosti Curves a Color Wheel. Program obsahuje pracovní prostor určený pro úpravu barev.[Adobe Premiere Pro]
🚀 Motion Graphics
DaVinci Resolve
DaVinci Resolve má samostatnou část věnovanou pohyblivé grafice s názvem Fusion. Jelikož se jedná o pokročilý nástroj, může vyžadovat určitou dávku trpělivosti a zaškolení, abyste pochopili, jak se s ním pracuje a jak funguje. Aplikaci však není třeba instalovat aplikaci samostatně. S Fusion integrovanou do DaVinci Resolve můžete snadno vytvářet a přesouvat věci a přitom zůstat v DaVinci Resolve.
Final Cut Pro
Pokud jde o Final Cut Pro, nenabízí speciální možnost pro pohyblivou grafiku. Namísto toho ji můžete vytvořit pomocí Apple Motion. Je jednoduchý na používání a obsahuje všechny možnosti, které potřebujete k vytvoření základní grafiky. Získáte výhodu výběru z široké škály pluginů a šablon pro vytváření pohyblivé grafiky mnohem jednodušší.
Adobe Premiere Pro
Pokud jde o pohyblivou grafiku, v Creative Cloudu od Adobe je jasnou volbou číslo jedna After Effects, což je ale samostatná aplikace. After Effects je „industry standard“ pro pohyblivou grafiku a jeho kompatibilita a propojení s Premiere Pro je vynikající. Musíte se však naučit ovládat novou aplikaci, což vyžaduje určitý čas a dovednosti.
💰 Cena a dostupnosť
DaVinci Resolve
DaVinci Resolve je k dispozici zdarma nebo v komerční verzi (DaVinci Resolve Studio), která stojí 295 USD – jednorázový poplatek. Bezplatná verze DaVinci Resolve je dostatečná i pro ty nejzkušenější profesionální editory. DaVinci Resolve je k dispozici pro Windows, Mac i Linux, což mu dává výhodu oproti Final Cut Pro i Adobe Premiere Pro.
Final Cut Pro
Final Cut Pro stojí jednorázový poplatek 299 USD, který se následně přiřadí k vašemu Apple ID a lze jej nainstalovat na více počítačů. Final Cut Pro je k dispozici pouze pro počítače Mac, takže pokud žádný nevlastníte, musíte si jej koupit také.
Adobe Premiere Pro
Adobe používá model předplatného (subscription) pro všechny své Creative Cloud aplikace a ceny jsou různé. Jen Premiere Pro vás bude stát 23,99 Eur měsíčně. Případně je možné objednat si celý Creative Cloud balíček se všemi aplikacemi (včetně After Effects, Photoshop, Illustrator, InDesign apod.) v ceně 59,99 Eur měsíčně. Není však možné objednat program a mít k němu časově neomezený přístup, je třeba platit měsíční poplatek.
Záver
Každý z nástrojů pro střih videa má své silné stránky: Premiere Pro je nejpoužívanější, Final Cut Pro X je nejrychlejší a DaVinci Resolve obsahuje „vše v jednom“.
Mějte také na paměti, že vývojáři těchto produktů v Adobe, Apple a Blackmagic Design neustále přinášejí nové aktualizace s vylepšeními. Naučte se důkladně jednu z těchto aplikací a ve světě editování videa se určitě neztratíte.

Vzdělávání
28.12.2021
Skillmea
Jak programovat hry. 8 nejpopulárnějších programovacích jazyků pro vývoj her
Tvorba her je tvůrčím úsilím, které vyžaduje jak kreativitu, tak technologické znalosti. Herní vývojáři musí znát programovací jazyky, které splňují specifické požadavky herního vývoje. Většina tvůrců her měla problém vybrat ideální programovací jazyk pro vývoj her, což je téma, kterému se věnují také IT kurzy a rekvalifikační kurzy zaměřené na tvorbu her. Je možné použít programovací jazyky jako C++, Python a další, přičemž některé jazyky vynikají efektivitou a výkonem více než jiné. Výběr programovacího jazyka pro herní vývojáře závisí na typu hry (konzole, počítač nebo mobil) a míře interaktivity. V tomto článku představíme top 8 programovacích jazyků pro vývoj her, což může být užitečné pro ty, kteří chtějí začít s vývojem her v rámci vzdělávacích kurzů.
Podle výzkumné zprávy od Market Research Future (MRFR), „Informace o trhu s videohrami podle herního zařízení, podle typu hry, podle koncového uživatele a regionu – prognóza do roku 2027“ byl videoherní trh oceněn na 155,9 miliard v roce 2019 a velikost odvětví má růst ročním tempem 14,5 % do roku 2026. Mezi dominantní hráče na videoherním trhu patří Ubisoft Entertainment, Electronic Arts, Qualcomm Wireless Communications Technologies, Nintendo nebo Activision Blizzard.
1. C#
C# je v současnosti jedním z nejoblíbenějších programovacích jazyků pro herní vývoj, zejména díky široké podpoře v různých herních enginech. Tento jazyk je vyhledávaný v IT kurzech pro vývoj her a stal se klíčovým mezi herními vývojáři. Jedním z důvodů jeho popularity je XNA framework vyvinutý společností Microsoft speciálně pro herní účely.
XNA framework je ideální pro tvorbu her na Windows a Xbox, což z C# činí všestranný nástroj. Navíc, herní engine Unity3D, který také podporuje C#, umožňuje vytvářet hry pro různé platformy, včetně iOS, Android, PlayStation a Windows. Populární hry vyvinuté pomocí C# zahrnují Pokemon Go a Super Mario Run, což inspiruje mnoho začínajících vývojářů, kteří mohou začít svou cestu s herním vývojem díky rekvalifikačním kurzům.
2. C++
Není žádným překvapením, že C++ je jedním z nejlepších jazyků pro vývoj her, zejména proto, že je to populární a flexibilní řešení. C++ je známý svou vysokou úrovní abstrakce, která umožňuje mít přesnou kontrolu nad tím, jak hardware počítače interaguje s kódem. C++ také poskytuje podrobnější kontrolu nad tím, jak systém zpracovává grafiku, což hraje v herním průmyslu velmi důležitou roli. Další klíčovou výhodou používání C++ je, že vám umožňuje optimalizovat speciální části herního designu a dát jim jejich vlastní abstrakce. Je to podobné, jak dát specifickým prvkům hry vlastní infrastrukturu a zdroje.
Tato úroveň podrobného vývoje her je u mnoha jiných jazyků náročná, ne-li nemožná. C++ byl použit k vytváření populárních her jako StarCraft, Football Pro nebo Counter-Strike.
3. Java
I když Java neposkytuje stejnou úroveň ovládání jako C++, mnozí považují Javu za nejlepší jazyk pro vývoj her. Popularita Javy je částečně způsobena její jednoduchostí použití, což z ní činí skvělé řešení pro mnohé nové herní vývojáře.
Java komunita také poskytuje velkou sbírku nástrojů a jiných open-source řešení. Díky tomu je vývoj her mnohem rychlejší, zvláště proto, že můžete najít kód, který již byl napsán k použití ve vaší hře. Ve srovnání s C++ nabízí Java jednoduché psaní, ladění, učení a kompilování.
Hry, jako například Mission Impossible III, Minecraft, FIFA 11 a Ferrari GT 3: World Track, byly všechny vytvořeny pomocí Javy.
4. JavaScript
Pokud jde o vývoj online her, jen málo jazyků je lepších než JavaScript. JavaScript si dobře rozumí s HTML i CSS, což usnadňuje vývoj her pro více platform.
Někteří programátoři považují JavaScript za pohodlné všestranné řešení, protože jej můžete použít k vytváření animací a interaktivních prvků. Online komunita JavaScriptu je také obrovská, takže můžete najít řadu předem navržených prvků, které můžete použít ve svých vlastních hrách.
JavaScript je jazyk, který stojí za herními hity jako American Girl, Angry Birds a Aquaria. Chcete-li začít s jazykem, vyzkoušejte náš kurz Dělej hry v JavaScriptu.
5. Python
Ačkoli není tak populární jako Java nebo C++, Python sa používá na vývoj her. Jeho knihovna PyGame je vhodná pro vývojáře, snadno se používá k vytváření her a umožňuje vývojářům rychle vytvářet prototypy her. Kromě toho, stejně jako Java a C++, i Python běží na principech OOP. Jeho jednoduchá křivka učení činí z Pythonu oblíbenou možnost pro mnohé začínající herní vývojáře.
Některé populární hry vytvořené pomocí Pythonu zahrnují Battlefield 2, Disney's Toontown Online, Eve Online a Frets on Fire.
6. HTML5
HTML není programovací jazyk, ale přesto je v našem žebříčku. HTML5 je jednou z nejlepších možností pro herní vývojáře pro vytváření aplikací a her pro různé platformy a prohlížeče. Dále jej lze snadno používat s JavaScriptem.
HTML5 je široce preferováno pro vývoj her pro své špičkové herní enginy. Herní frameworky včetně Construct 2, ImpactJS, Phaser, Turbulenz a Booty5 převzaly zodpovědnost za proces vývoje her v HTML5.
Některé populární hry vytvořené pomocí HTML5 zahrnují Cookie Clicker, Gods Will Be Watching, World Cup Penalty 2018.
7. UnrealScript
Unreal Engine vyvinul programovací jazyk UnrealScript nebo UScript. Stejně jako Java, i UnrealScript je objektově orientován bez vícenásobného dědění. Hlavní herní platformy včetně Windows, Android, Linux a Playstation používají UnrealScript. V roce 2014 však Epic Games oznámily, že Unreal Engine 4 nebude podporovat UnrealScript.
Některé populární hry vyvinuté pomocí UnrealScript zahrnují Advent Rising, America's Army, The Wheel Of Time, Batman-Arkham Knight a jeho série.
8. Lua
Lua je lehký, vysokoúrovňový a multiplatformový programovací jazyk, který se snadno spouští, díky čemuž je zábavné a efektivně jej používat pro vývoj videoher. Může být navržen tak, aby se dal vložit do mnoha aplikací, díky čemuž je pro vývojáře a hráče pohodlné upravovat hru.
Herní enginy, jako například Gideros mobile, Corona SDK a CryEngine, používají Lua jako svůj primární programovací jazyk.
Některé populární hry vyvinuté pomocí jazyka Lua jsou Age of Conan, American Girl, Angry Birds a Aquaria.
Zajímá tě herní vývoj a chceš se mu začít věnovat? Určitě si prohlédněte některé z našich kurzů věnované právě tvorbě her v Unity3D, JavaScriptu či GameMaker Studio.

Vzdělávání
20.12.2021
Skillmea
Co je etický hacking?
Slovní spojení etický hacking se na první pohled může jevit jako oxymoron. V tomto blogu ti však vysvětlíme, co je to etický hacking, na jakých principech je postaven, jak se liší od toho neetického hackingu a jak může být přínosný pro firmy.
Když vznikl pojem „hacker“, popisoval softwarové inženýry, kteří vyvinuli kód pro sálové počítače. Nyní to znamená zkušeného programátora, který se pokouší získat neoprávněný přístup k počítačovým systémům a sítím využitím slabých míst v systému. Hackeři píší skripty, aby pronikli do systémů, prolomili hesla a ukradli data.
I když se hackování stalo pojmem, který nejčastěji popisuje škodlivé a neetické aktivity, nemusí tomu tak být. Hacker může tyto dovednosti stále dobře využít. V tomto článku se podíváme na etické hackování a ukážeme ti, jak můžeš začít svou cestu stát se etickým hackerem.
Co vlastně dělají etičtí hacker?
Etický hacking je znám také jako white hat hacking nebo penetrační testování. Může to být velmi zajímavá kariéra, protože etičtí hackeři tráví svůj pracovní den učením se, jak fungují počítačové systémy, odhalováním jejich zranitelných míst a zkoušením vkrást se do nich beze strachu ze zatčení.
Na rozdíl od neetických hackerů, kteří jsou obvykle motivováni finančním ziskem, etičtí hackeři mají za cíl pomoci firmám (ale i společnosti jako celku) udržovat jejich údaje v bezpečí. Firmy si najímají etické hackery, aby našli zranitelná místa ve svých systémech a aktualizovali chybný software, aby nikdo jiný nemohl použít stejnou techniku k opětovnému proniknutí.
Jako etickému hackerovi se ti buď podaří nabourat do systému a poté ho opravit, nebo se pokusíš nabourat do systému a nepodaří se ti to. Oba výsledky znamenají vítězství pro etického hackera a firmu, protože firemní síť a údaje jsou v konečném důsledku bezpečné.
Řekněme si ještě jaký je rozdíl mezi etickým hackerem a penetračním testerem. Zatímco termín etický hacking lze použít k popsání celkového procesu hodnocení, provádění, testování a dokumentování založeného na množství různých hackerských metodologií, penetrační testování je jen jeden nástroj nebo proces v rámci etického hackingu.
Hledají zranitelná místa
Zranitelnost jsou bugy nebo chyby v softwaru, které lze využít k získání neoprávněného přístupu do sítě nebo počítačového systému. Mezi nejběžnější zranitelnosti patří:
• zastaralý software,
• nesprávně nakonfigurované systémy,
• nedostatečné šifrování údajů.
Některé zranitelnosti lze snadno otestovat, protože chyby již byly zdokumentovány. V těchto případech musí penetrační tester provést pouze skenování systému, aby zjistil, zda v systému existuje chyba a aktualizovat software.
Další zranitelnosti však mohou být neznámé a penetrační tester použije skripty a další nástroje, aby maximálně otestoval systém a zjistil, jestli se nějaké chyby objeví.
Ukazují metody používané hackery
Etičtí hackeři se mohou vžít i do role učitele. Mnoho firem a zaměstnanců ví jen málo o hrozbách kybernetické bezpečnosti ao tom, jak jejich jednání může zabránit hrozbě nebo pomoci hackerovi ukrást data.
Etičtí hackeři pořádají kurzy o kybernetické bezpečnosti a varují zaměstnance před novými hrozbami, když je objeví. Vzdělávání je obzvlášť účinné proti phishingu a jiným kybernetickým útokům typu sociálního inženýrství, které vyžadují, aby útočníkův cíl (člověk) podnikl kroky, aby byla jeho hackerská aktivita umožněna.
Když jsou zaměstnanci informováni o potenciální hrozbě, existuje větší šance, že ji bude možné zastavit dříve, než infikuje systém.
Pomáhají předcházet kybernetickým útokům
Etičtí hackeři také spolupracují s ostatními členy bezpečnostního týmu na vytvoření bezpečnější infrastruktury pro podnik.
Etičtí hackeři vědí, jaké druhy hrozeb existují, a mohou týmu pomoci při výběru nástrojů a vytváření bezpečnostních politik, které mohou zabránit hrozbám, o kterých možná ještě ani nevědí. Mohou také pomoci s nastavením systémů pro zálohování a obnovu, které lze použít v nejhorším případě.[Image]
Klíčové principy etického hackingu
Hranice mezi black hat (nebo neetickým) hackingem a white hat (nebo etickým) hackingem se může zdát nejasná. Koneckonců, existuje také gray hat hacking, které se nachází někde mezi těmito dvěma.
Jako etický hacker bys měl dodržovat několik zásad:
• Dodržuj zákon: hackování je etické pouze tehdy, pokud máš povolení k provedení hodnocení bezpečnosti systému, který hackuješ.
• Poznej rozsah projektu: chovej se jen v intencích smlouvy, kterou máš se společností. Zjisti přesně, co máš testovat a testuj pouze tyto systémy.
• Nahlas všechna slabá místa: nahlas všechna slabá místa, která najdeš a navrhni způsoby, jak je opravit.
• Respektuj jakékoli citlivé údaje: penetrační tester často testuje systémy, které uchovávají citlivé údaje a bude muset podepsat smlouvu o mlčenlivosti (NDA).
Proč je etický hacking důležitý?
Záměrným zjištěním zneužití a slabin v počítačových sítích organizace je v podstatě možné opravit je dříve, než je zneužije neetický hacker. Etičtí hackeři tedy pomáhají organizacím identifikovat a eliminovat hrozby zlepšováním celkové bezpečnosti IT v organizaci.
Samozřejmě nejsou to jen údaje, které jsou v sázce, pokud jde o počítačovou kriminalitu. Ve zprávě Centra pre strategické a medzinárodné štúdie a spoločnosti McAfee v oblasti bezpečnostního softwaru z roku 2020 bylo zjištěno, že ztráty z počítačové kriminality dosáhly v roce 2020 přibližně 945 miliard USD. Jen pro srovnání, v roce 2018 to bylo zhruba 522 miliard USD, takže nárůst je znepokojivý. Tyto rostoucí náklady se připisují lepšímu vykazování, jakož i efektivnějším technikám hackerů.
Kromě ztráty údajů a peněz může počítačová kriminalita poškodit veřejnou bezpečnost, poškodit ekonomiky a podkopat národní bezpečnost. Je zřejmé, že je nezbytné chránit organizace a jejich údaje a etické hackování může v této ochraně hrát klíčovou roli.
Druhy etického hackingu
Existuje několik etických hackerských metod a základních oblastí, které může profesionál použít. Níže uvádíme některé z nejběžnějších typů etického hackování:
• Hackování webových aplikací. Webové aplikace jsou sdíleny přes síť (jako je internet nebo intranet) a někdy jsou založeny na prohlížeči. I když jsou pohodlné, mohou být zranitelné vůči útokům skriptů a etičtí hackeři takové slabiny testují.
• Hackování webového serveru. Webové servery provozují operační systémy a aplikace, které hostují webové stránky a připojují se k back-end databázím. V každém bodě tohoto procesu existují potenciálně slabá místa, která musí etičtí hackeři otestovat, identifikovat a doporučit opravy.
• Hackování WIFI bezdrátové sítě. Všichni známe bezdrátové sítě – skupinu počítačů, které jsou bezdrátově připojeny k centrálnímu přístupovému bodu. S touto vymožeností však přichází řada potenciálních bezpečnostních nedostatků, které musí white-hat hackeři hledat.
• Hackování systému. Přístup k zabezpečené síti je jedna věc, ale hackování systému se zaměřuje na získání přístupu k jednotlivým počítačům v síti. Etičtí hackeři se přesně o to pokusí a zároveň navrhnou vhodná protiopatření.
• Sociální inženýrství. Zatímco ostatní metody se zaměřují na přístup k informacím prostřednictvím počítačů, systémů a sítí, sociální inženýrství se zaměřuje na jednotlivce, lidi. Často to znamená manipulaci lidí, aby předali citlivé údaje nebo poskytli přístup, aniž by měli podezření na špatný úmysl.
Jaké pracovní pozice může obsadit etický hacker?
Firmy všech velikostí a odvětví se obávají bezpečnosti své sítě. Pokud stále dochází k narušení bezpečnosti a firmy budou mít stále citlivé údaje, etičtí hackeři budou žádáni, takže trh práce pro ně vypadá dobře iv budoucnosti.
Některé větší podniky mají mezi zaměstnanci etických hackerů, kteří celý den provádějí bezpečnostní testy a penetrační testy. V jiných společnostech může být etické hackování pouze součástí práce, zatímco většinu času trávíte konfigurací sítí a nastavováním nových systémů. Některé z nejpopulárnějších pozic etických hackerů zahrnují:
• Penetrační tester
• Security Analyst
• Etický hacker
• Bezpečnostní konzultant
• Bezpečnostní inženýr
• Bezpečnostní architekt
• Analytik informační bezpečnosti
• Manažer informační bezpečnosti
Závěr
Pokud tě kariéra v tomto odvětví zatím láká, možná tě také zajímá, jak se naučit etický hacking. Většina etických hackerů, penetračních testerů a white-hat hackerů se pustí do etického hackingu, protože je zajímá, jak funguje internet a informační bezpečnost. Jedna věc, kterou musí etický hacker vědět, je kybernetická bezpečnost.
Jelikož etický hacker se zabývá i softwarovými zranitelnostmi a možná bude muset psát skripty, které mu pomohou s tímto úkolem, budeš se muset naučit i nějaký programovací jazyk (pravděpodobně to bude více jazyků). Pro etické hackery jsou doporučené jazyky jako Python, C, C++ nebo JavaScript.
Práce s terminálem, scriptování v Bashi jsou také silně doporučeno, stejně tak nástroje pro testování zranitelnosti jako Metasploit a OpenVAS. Mnoho užitečných nástrojů a postupů etického hackingu se naučíš v našem online kurzu Úvod do etického hackingu.
Nejdůležitějším požadavkem je však zvědavost. Takže buď zvědavý a hodně štěstí při etickém hackování!

Vzdělávání
25.11.2021
Skillmea
Jak analyzovat data. 11 nejlepších nástrojů pro analýzu dat
Objem údajů, které se vytvářejí dennodenně, každý rok exponenciálně roste. V průměru každý z nás vytvoří každou vteřinu minimálně 1,7 megabajtu dat. Mnohé z těchto údajů shromažďují firmy, pro které znamenají klíčovou roli při rozhodování a strategickém plánování. V tomto kontextu je správná analýza dat zásadním faktorem pro efektivní využití dat.
Bez správných nástrojů se však data nevyužívají a jen zabírají místo. Proto přicházejí na scénu nástroje pro statistickou analýzu dat. Umožňují datovým vědcům a datovým analytikům shromažďovat a analyzovat data, aby je přeměnili na užitečné informace pro rozvoj podnikání či přijímání správných rozhodnutí.
K dispozici je široká škála nástrojů pro analýzu dat. Některé z nich jsou programovací jazyky, které jsou oblíbené mezi datovými vědci, protože se snadno používají a dobře analyzují data. Mezi tyto nástroje patří například programovací jazyky, které se často vyučují v IT kurzech a které zahrnují Python, R nebo SQL. Některé nástroje jsou knihovny pro tyto programovací jazyky, které zjednodušují analýzu údajů. A některé jsou samostatné aplikace, které běží v počítači nebo ve webovém prohlížeči.
Výběr správných nástrojů pro analýzu dat
Před výběrem nástroje pro analýzu údajů je třeba zvážit několik otázek, zejména:
• Jaký druh dat analyzujete? Jsou to jednoduché číselné údaje uložené v tabulkách a databázích, nebo kvalitativní údaje s otevřeným koncem, jako jsou konverzace v sociálních médiích, které vyžadují analýzu pomocí modelů strojového učení k vytvoření přehledů?
• Kolik dat analyzujete? Pokud jsou údaje, které potřebujete analyzovat, omezené, práci zvládne téměř každý nástroj. Pokud však plánujete analyzovat big data, budete muset k analýze dat použít specifické nástroje.
• Jaké technické znalosti jsou potřebné k provedení analýzy? Pokud ovládáte programovací jazyk, jako je Python, R, Java nebo SQL, pak máte mnoho možností, pokud jde o výběr nástroje pro statistickou analýzu dat. A pokud nejste technický nebo nemáte zájem o učení se jazyku, máte také několik možností, protože jsou k dispozici tzv. "no-code" nástroje, které můžete použít.
• V jakém formátu chcete výsledky? Chcete vidět své výsledky ve formátu tabulky nebo byste raději generovali grafické zobrazení výsledků?
Nejpopulárnější nástroje pro analýzu dat
Po zodpovězení těchto otázek si uděláte přehled o různých analytických nástrojích a zvolíte ten nejvhodnější pro vaše potřeby. V seznamu níže nyní uvedeme populární nástroje pro analýzu dat, která by vám mohla pomoci. Na výběr jsou jak aplikace využívající pokročilé algoritmy, tak nástroje dostupné v rámci online kurzů, které vás provedou jednotlivými kroky analýzy.
1. Python
Python je jedním z nejpoužívanějších programovacích jazyků pro analýzu dat a je také vyhledávaný ve světě vzdělávacích kurzů zaměřených na programování a práci s daty. Je to interpretovaný, univerzální, vysokoúrovňový jazyk, který lze použít pro procedurální, funkční i objektově orientované programování. Tato flexibilita je jedním z důvodů, proč je Python oblíben u programátorů s různým zaměřením. Navíc, jeho jednoduchá syntax, která je téměř jako přirozený jazyk, z něj činí ideální volbu nejen pro profesionály, ale i pro začínající vývojáře, kteří se často přihlašují na online kurzy Pythonu.
Co však dělá Python skvělým jazykem pro analýzu dat, jsou všechny knihovny třetích stran, které můžete do svého projektu přidat zdarma. Mnohé z těchto knihoven, jako jsou Matplotlib, PyTorch a Pandas, jsou navrženy pro zpracování dat, což znamená, že pro analýzu dat musíte napsat méně kódu. Tyto knihovny jsou často také součástí různých IT kurzů, kde se zaměřují na efektivní vizualizaci a zpracování dat.
2. Matplotlib
Matplotlib je knihovna Pythonu, která usnadňuje vizualizaci dat a grafické vykreslování. Můžete ji jednoduše nainstalovat na jakýkoli operační systém, který podporuje Python, včetně Mac, Windows a Linux. Po nainstalování můžete dlouhé seznamy čísel převést na snadno srozumitelné koláčové grafy, tepelné mapy, histogramy a jiné typy vizualizací, které jsou připraveny k použití v sestavách nebo publikování online. Statistická analýza dat s Matplotlib tak získává atraktivní a přehledné zobrazení.
Matplotlib může také vygenerovat uživatelské rozhraní pro vaši grafiku s nabídkou, kterou můžete použít pro přizpůsobení grafiky bez psaní dodatečného kódu. Tato knihovna je často součástí kurzů programování, kde si studenti mohou vyzkoušet vytvoření interaktivních vizualizací a pochopit, jak vizualizovat data pro efektivní rozhodování.
3. PyTorch
PyTorch je open source knihovna Pythonu, která se používá k vytváření, trénování a spouštění modelů strojního učení. Používá tenzory podobné polím pro kódování vstupů, výstupů a parametrů modelů. Tenzor je kontejner pro data, který může tyto údaje reprezentovat v libovolném počtu dimenzí, což z něj činí velmi flexibilní nástroj pro analýzu dat.
Další výhodou PyTorch je, že může spouštět modely strojového učení pomocí počítačového GPU a nikoli CPU. To znamená, že model strojového učení PyTorch vám může poskytnout report 4 až 5krát rychleji než jiné nástroje pro analýzu údajů, které využívají pouze zpracování CPU.
4. Pandas
Pandas je další knihovna Pythonu a je to švýcarský armádní nožík pro manipulaci s údaji. S pandas můžete změnit nestrukturované údaje z více zdrojů na 2D objekt v paměti zvaný DataFrame.
Když už máte data v DataFrame, můžete je rychle filtrovat, vyhledávat, segmentovat a segregovat. Můžete také sloučit a spojit dva různé DataFrame.
5. Jupyter Notebook
Jupyter Notebook je webová aplikace s otevřeným zdrojovým kódem, ve které můžete spouštět Python, R a další programovací jazyky v interaktivním prostředí. Jelikož se jedná o webovou aplikaci, umožňuje interaktivní spolupráci mezi uživateli.
Nazývá se to „notebook“, protože umožňuje analytikům dat nejen ukládat a spouštět kód v prohlížeči, ale přidává také vysvětlující text, obrázky a další podpůrné informace.
Zápisníky Jupyter slouží jako výpočetní záznam mezi spolupracovníky a vytvořené záznamy lze uložit jako soubory JSON. Tyto soubory pak lze použít ke sledování každého kroku procesu. O PyTorch, Pandas a tvorbě grafů v Matplotlib se více dozvíš v našem online kurzu Python Data Science.
6. R
R byl navržen speciálně pro potřeby komunity zabývající se datovou analýzou a statistikou. Jazyk R je vhodný pro strojní učení, vizualizaci údajů a statistickou analýzu. Obrovskou výhodou jazyka R je právě jeho obrovská komunita.
R je sada nástrojů pro manipulaci s údaji, provádění výpočtů a generování grafiky. Dodává se s výkonnými možnostmi zpracování a ukládání dat, jakož i flexibilní sadou grafických nástrojů pro generování tabulek a grafů, které jsou připraveny pro publikování v sestavách.
Pokud si vyberete jazyk R, neuděláte určitě chybu, zejména proto, že byl od základů vytvořen právě pro datovou analýzu.
7. SQL
SQL, což je zkratka pro Structured Query Language, je programovací jazyk, který byl vytvořen pro interakci s relačními databázemi. Z tohoto důvodu a také vzhledem k tomu, že firmy ukládají většinu svých údajů v databázích, je SQL základním nástrojem, který datoví vědci a datoví analytici používají pro tvorbu reportů a analýzu dat. SQL je navíc jednoduchý jazyk k učení, a proto se často vyučuje v rekvalifikačních kurzech online, kde se zaměřuje na efektivní práci s daty.
Dotazy, které do SQL píšete, jsou téměř jako anglické věty, což usnadňuje práci i méně zkušeným uživatelům. Téměř každý jiný programovací jazyk navíc obsahuje knihovny, které můžete použít k interakci s databázemi. Tato široká podpora činí SQL výkonným nástrojem, který je často zahrnutý i v nejlepších rekvalifikačních kurzech pro práci s daty, protože umožňuje rychlou analýzu velkých datových souborů.
8. D3.js
D3.js je open-source JavaScriptová knihovna pro vytváření vlastních vizualizací ve webovém prohlížeči. Spolu s JavaScriptem využívá HTML, škálovatelnou vektorovou grafiku a CSS, což umožňuje webovým vývojářům provádět analýzu dat a tvorbu interaktivních grafů přímo v prohlížeči, aniž by se museli učit nový jazyk. D3 je zkratka pro "Data Driven Documents" a umožňuje vývojářům propojit data na HTML dokumenty pomocí Document Object Modelu (DOM) a poté transformovat dokument na základě dat, která používá.
D3.js také podporuje interakci, animaci, anotaci a kvantitativní analýzu. I když lze technologie, které D3 používá, poměrně snadno pochopit, knihovna obsahuje více než 30 modulů a 1 000 metod vizualizace, jejichž zvládnutí může vyžadovat čas. D3.js je součástí některých rekvalifikačních kurzů online zaměřených na datovou analýzu a vizualizaci dat, kde si studenti mohou osvojit vytváření interaktivních a dynamických vizualizací.
9. MATLAB
MATLAB používá vysokoúrovňový programovací jazyk pro matematické modelování, numerické výpočty a vizualizaci dat. Jeho název je zkratkou pro „maticovou laboratoř - matrix laboratory“, protože jde o maticový jazyk. Matematické matice jsou datové struktury, které dokážou vyřešit mnohé technické výpočetní problémy efektivněji než jiné skalární programovací jazyky.
MATLAB můžete použít na řadu různých úkolů, jako je vykreslování údajů, vývoj algoritmů, vytváření modelů strojního učení, interakce s programy napsanými v jiných jazycích a analýza množin dat. Díky jeho pokročilým matematickým funkcím existuje mnoho technických rolí, které používají MATLAB, včetně softwarových inženýrů a datových analytiků.
10. Tensor Flow
TensorFlow je open-source platforma strojového učení a analýzy dat, kterou vytvořil tým Google Brain. Používá se pro numerické výpočty a implementaci neuronových sítí s hlubokým učením. Kód pro TensorFlow je napsán v C++, ale poskytuje API, ke kterému lze přistupovat pomocí mnoha jiných programovacích jazyků včetně Python, Go, Java, R, JavaScript a dalších.
TensorFlow dokáže trénovat a spouštět modely strojového učení pro rozpoznávání obrázků, klasifikaci ručně psaných číslic, vkládání slov, opakující se neuronové sítě, překlad jazyka, zpracování přirozeného jazyka a simulaci. A namísto toho, abyste se museli zabývat podrobnostmi vytváření vlastních algoritmů, můžete si vytvořit své vlastní modely pomocí TensorFlow.
11. Tableau
Tableau je přední nástroj Business Intelligence na trhu, který se používá pro analýzu a vizualizaci údajů v jednoduchém formátu.
Tableau je nástroj pro analýzu dat, který se používá k vytváření kvalitních vizualizací dat pro business intelligence. Dokáže extrahovat data z mnoha zdrojů, včetně Microsoft Excel, PDF souborů, různých typů databází nebo dokonce souborů uložených na AWS.
Po extrahování dat k nim může přistupovat aplikace Tableau Desktop. Potom jej můžete použít ke generování dashboardů a vizualizací v softwaru. Data mohou být také publikována na Tableau Server, kde k nim lze přistupovat z jakéhokoli místa, včetně mobilních zařízení. A to vše můžete udělat bez psaní jakéhokoli kódu.
Závěr
Nástroje pro analýzu dat vám pomohou objevovat trendy a vzorce, na jejichž základě budete umět dělat lepší rozhodnutí. K dispozici je široká škála nástrojů, od složitých programovacích jazyků až po aplikace, které vyžadují velmi málo technických znalostí. Výběr je jen na vás.

Vzdělávání
16.11.2021
Skillmea
Co dělá DevOps Engineer?
Na základě některých statistik se předpokládá, že poptávka po softwarových inženýrech do roku 2029 poroste o 22%. Tato poptávka po softwarových inženýrech a webových či mobilních aplikacích, které vytvářejí, vedla k mnoha novým pracovním pozicím a inovativním, efektivnějším vývojovým procesům – jako například DevOps.
Zajímá tě, co je to DevOps, co dělá takový DevOps Engineer (inženýr), kolik vydělává a jaké dovednosti potřebuje? Čti dál a dozvíš se víc.[Image]Co je DevOps?
DevOps je spojení slov Development (vývoj) a Operations (provoz). Je to speciální metoda vývoje softwaru, která spojuje procesy, lidi a technologie, díky čemuž mohou firmy produkovat kvalitní software, služby a produkty.
DevOps-áci používají nástroje, procesy a metody vývoje k zajištění efektivního vývoje aplikací. Hrají důležitou roli v každé fázi procesu vývoje, od nápadu až po implementaci a údržbu.
DevOps označuje způsob vývoje softwaru, který zajišťuje, že vše běží hladce v každé fázi vývoje. Před představením DevOps v roce 2009 vývojářské týmy obvykle sestavovaly každou část aplikace nezávisle. Jeden tým by se například zabýval strukturou databáze, zatímco jiný vytvořil frontend nebo bezpečnostní prvky. I když to bylo efektivní, často to vedlo k problémům, kdy byly tyto různé části spojeny do jednoho celku.
DevOps se snaží tento problém vyřešit tím, že všechny účastníky vývoje spojí dohromady. Můžeš si to lehce představit jako stavbu domu. Standardně bys měl různé dodavatele, kteří by dělali různé práce: zedníci, elektrikáři, instalatéři, malíři atp. U DevOps modelu však tito dodavatelé spolupracují, diskutují o každé fázi vývoje a pracují spolu a táhnou za jeden provaz.
Výsledkem je, že konečný produkt je efektivnější, kvalitnější a ušetří i čas, protože každá složka se pojí s ostatními. DevOps Engineer zajišťuje, že se to všechno děje hladce a konzistentně během celého životního cyklu vývoje. DevOps specialisté tedy používají různé nástroje, procesy a metody vývoje, aby zajistily efektivní vývoj aplikací. V každé fázi procesu vývoje (od nápadu až po implementaci a údržbu) hrají významnou roli.
Jelikož celý vývoj aplikace je v rámci jednoho týmu, vývojáři jsou schopni rychleji komunikovat mezi sebou, ale také kolaborovat se zákazníkem, což znamená častější vydávání nových verzí vyvíjeného softwaru.
Funkce DevOps
DevOps specialista podporuje komunikaci, spolupráci a sdílení odpovědnosti napříč všemi stranami během životního cyklu vývoje. Hlavní výzvou, které čelí DevOps-áci, je sjednotit všechny účastníky vývoje, což jsou frontend a backend developeři, UI/UX designéři, testeři, lidé zodpovědní za bezpečnost produktu, ale také obchodníci, zákaznický servis či další klíčové osoby.
V DevOps kultuře jsou všichni tito účastníci stejně důležití a jejich vstupy do vývoje mají stejnou hodnotu. DevOps-ák musí zajistit, že je s tím celý tým ztotožněn, podporuje to a samozřejmě zejména praktikuje.
Jaké techniky používají DevOps-áci?
Nejčastěji jsou využívány následující postupy či technologie:
• continuous integration, continuous deployment (CI/CD),
• kontejnerizace,
• monitorování.
Ve zkratce si řekněme o každé z výše uvedených technologií.
CI/CD
Zavádí automatizaci do softwarového vývoje. Pomocí skupiny různých nástrojů tak lze zajistit automatické sestavování verzí, jejich kontrolu a reporting kvalit konkrétní verze. Po sestavení a otestování lze nasadit verzi do produkčního prostředí. To je technika Continuous Integration. Jinými slovy, změny se provedou a integrují okamžitě.
"CD" se může vztahovat i na Continuous Delivery. Změny provedené v aplikaci se před odesláním do úložiště (např. GitHub) testují na chyby. Následně jsou umístěny do živé produkce. Continuous Deployment znamená automatické odesílání změn provedených vývojářům z úložiště jako například. GitHub do produkce, kde jej mohou koncoví uživatelé používat.
Kontejnery
Kontejnery poskytují způsob izolace procesů od zbytku softwaru. Každý kontejner funguje v podstatě jako virtuální stroj, který spouští jednu část celkového procesu. Protože kontejnery lze velmi rychle zapnout a vypnout, kontejnerizace usnadňuje vytváření, nasazování a spouštění aplikací. DevOps engineer musí rozumět kontejnerizaci, protože má vliv na to, jak se produkt vytváří, upravuje a testuje.
Při vytváření kontejneru by mělo platit pravidlo, že jeden kontejner je jedna služba. Abychom docílili těchto vlastností kontejnerů, musíme dodržet 3 hlavní principy kontejnerizace: standardnost (Standard), jednoduchost (Lightweight) a izolovanost (Isolated).
V dnešní době je velmi populární přechod na mikroservisově orientovanou architekturu. U této architektury je funkcionalita softwaru rozdělena do menších částí - mikroservisů. Cílem je vytvoření aplikace, která bude co nejvíce modulární. Bude to znamenat její zjednodušení, udržovatelnost a také škálovatelnost. Funkcionalita aplikace se rozdělí do jednotlivých mikroservisů, kde každý má na starosti pouze jednu, oddělenou část softwaru. Pokud bude nutná změna aplikace, tyto mikroservisy je relativně snadné upravit. Provede se jen požadovaná změna, upraví se daný mikroservis a opětovně je nasazen. Při takovém přístupu se vyskytuje méně chyb, výpadků a má to kladný vliv na testování a hledání chyb v softwaru.
Monitorování
Monitorování zahrnuje používání systému, který umožňuje sledovat celý vývojový ekosystém a upozorní tě, pokud se něco pokazí. S dobře nastaveným monitorováním můžeš rychle řešit problémy pomocí analýzy základních příčin, která přesně určí, kde problém začal. Monitorování ti také umožňuje zjistit, jak se různé systémy navzájem ovlivňují, ať už běží současně nebo postupně.
Tvá práce jako DevOps specialisty bude téměř nemožná bez komplexního monitorovacího řešení. Řešení problémů bude rychlejší a efektivnější.[DASA DevOps Competency model (zdroj: DASA)]
Dovednosti DevOps specialisty
Technické dovednosti jsou nezbytností. I když se v DevOps prostředí a IT obecně neustále objevují nové technologie a nástroje, dobrý DevOps inženýr by měl mít kvalitní znalosti v těchto oblastech:
• verziování, systém správy verzí (jako Git, Github, Bitbucket, Svn atd.),
• Continuous integration (Jenkins, Bamboo, VSTS),
• koncepty kontejnerů (Docker),
• orchestrace kontejnerů (Kubernetes, Swarm, Openshift),
• cloud (AWS, Azure, GoogleCloud, Openstack),
• základy sítí, Linux (základy OS), Bash,
• základy programování (např. Python, Design Patterns).
DevOps inženýři musí být schopni psát bezpečný kód na ochranu aplikací před útoky, jakož i na obranu před běžnými zranitelnostmi kybernetické bezpečnosti. Stejně jako v jiných technických prostředích, klíčovým prvkem DevOps je také automatizace. Mnoho opakujících se a manuálních úkolů prováděných tradičnějšími systémovými administrátory lze automatizovat pomocí jazyků jako Python, Ruby, Bash či Shell.
Nezapomínej ani na soft skill dovednosti jako komunikační dovednosti, dobrou organizaci, ochotu spolupracovat, flexibilitu, prezentační dovednosti nebo to, že zákazník je na prvním místě.
Mzda DevOps specialisty se podle portálu platy.sk pohybuje v závislosti na regionu a seniority na úrovni od 2.000 Eur výše. Jedná se o velmi žádanou pozici, poptávka po DevOps inženýrech v posledních letech značně vzrostla.[Image]Jak se stát DevOps specialistou
Aby ses stal DevOps specialistou, musíš získat znalosti a zkušenosti potřebné pro práci s různými technologiemi. Klíčem je naučit se dovednosti, aplikovat je a vybudovat si portfolio, kterým se umíš odprezentovat.
Náš seznam výše v článku se zdá být vyčerpávající a nekonečný. Jak jsme již zmiňovali, v jedné oblasti můžeš být expertem ao jiných víš toho málo. To je naprosto v pořádku. Základní znalosti z každé oblasti jsou dobrým začátkem. Například, pokud jsi softwarový inženýr, určitě jsi dobrý v programování. Nemělo by být pro tebe obtížné zvládnout práci admina, protože některé činnosti jsi už určitě mohl vykonávat ve své práci.
Stejně tak, pokud jsi síťový inženýr, nebudeš mít problém naučit se více o bezpečnosti, virtualizaci a správě infrastruktury. Každá z těchto dovedností spolu souvisí. Cesta k tomu, abyste se stali DevOps specialistou je dlouhá, ale stojí za to. A neexistují žádné zkratky.